论文情况概述
该论文是2021年发布在ICLR上的文章, 全名为:
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
是由Google brain所完成的工作, 在这篇论文中提出了名为vit的架构(vision transformer), 该架构将nlp领域中常用的transformer架构迁移到了cv领域, 在这篇论文中, 作者尝试了vit在图像分类方面的效果,性能显示是比大多数sota要好的
在该博客中会首先对vit的大致架构先进行整理, 随后进行论文的解读
论文链接:https://arxiv.org/abs/2010.11929
代码链接(非官方):https://github.com/ViceMusic/vit-pytorch
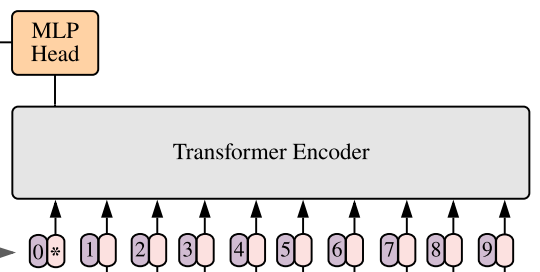
vit结构图如所示:
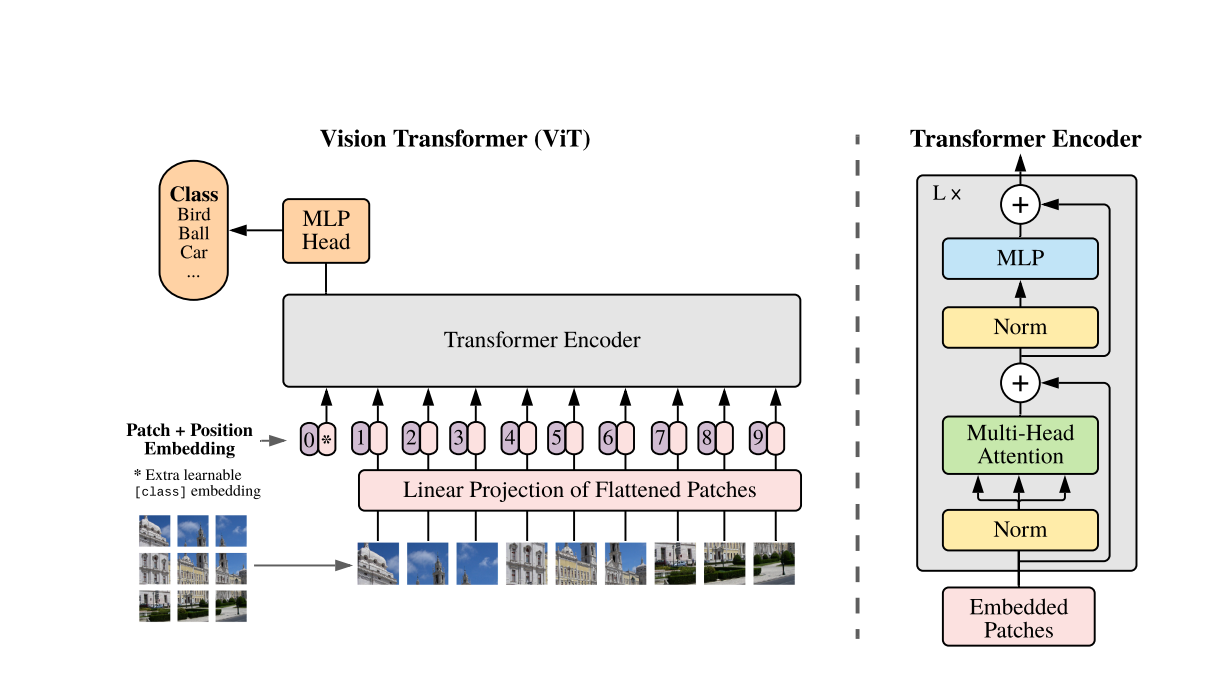
1. 论文解读
1.1. 论文的研究背景
尽管transformer架构已经成为了NLP任务中占据主要地位的问题解决方法, 通过在语料库上进行预训练, 以及在特定的下游任务上完成微调. attention机制在其中起到了全局观测的效果, 同样具有较长的感知长度(RNN, 经典例子: 马尔可夫模型), 并且保持了并行计算的一个特点(CNN), 集合了两者的优势(2024.2注: 腾讯的实验室好像提出了一个新的cnn架构, 在效果上和Transformer不相上下, 还没来得及看)
但是在图像识别领域, 注意力机制的应用虽然已经有所应用, 一些对CNN的架构使用了注意力机制作为补充(Wang et al., 2018; Carion et al., 2020), 一些则直接替换了卷积部分 (Ramachandran et al., 2019; Wang et al., 2020a).这些方法在cv领域的应用还十分有限, 虽然在理论上是卓有成效的, 但是事实上, 这种使用也消耗了大量的计算资源.
受到transformer架构的鼓舞, 研究团队尝试将Transformer架构直接投入了Cv工作并发现, 在图像分类任务上使用纯transformer架构可以起到一个不错的结果. 在足够大的数据集上训练以后, 可以和CNN的sota达到一个不相上下的效果
此外, 研究团队也找到了一个相关的工作: the model of Cordonnier et al. (2020) , 该工作在原理上和vit很接近, 在图像划分阶段的处理方式有所区别, 不过在这里就不展开解释另一个模型了.
为什么要平白无故的引入这样一个机制:
Transformer模型具有自注意力机制,可以捕获输入序列中的全局依赖关系,这种机制在自然语言处理任务中已经被证明是非常有效的。通过将Transformer直接应用于图像领域,可以使得模型在处理图像时也能够更灵活地学习特征之间的关系,而不仅仅局限于局部信息。
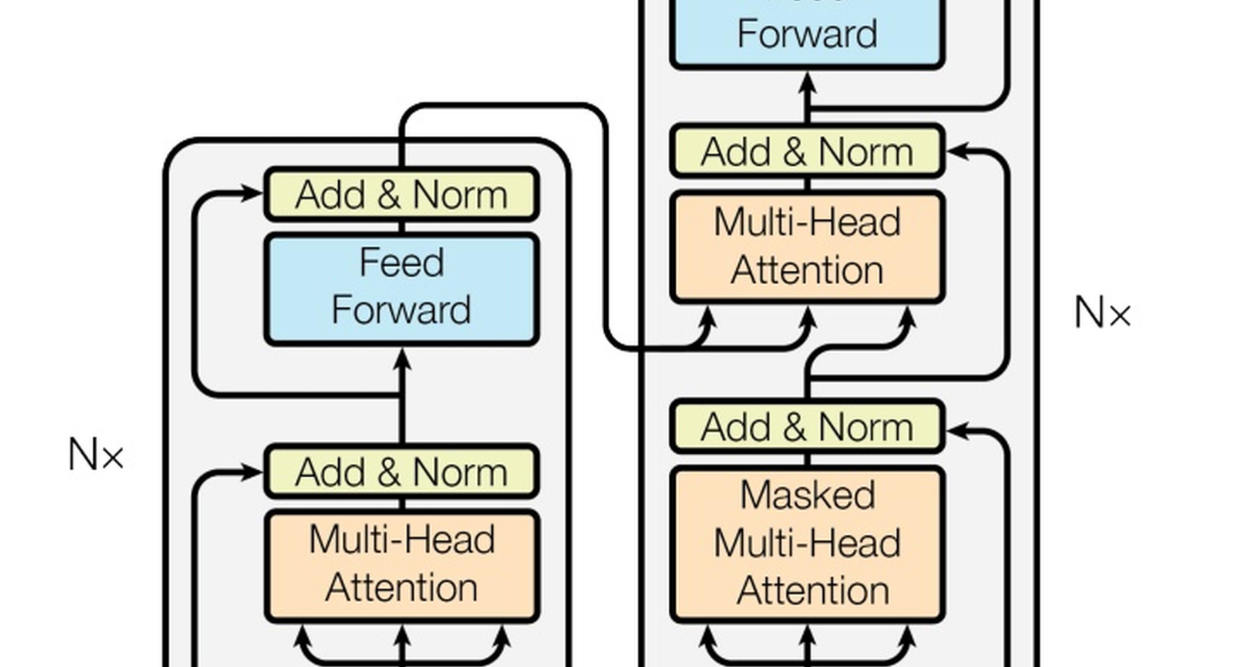
1.2 实验

1.2.1: 实验的设置
研究团队使用了ILSVRC-2012 ImageNet数据集,其中包含1k个类别和130万张图片(我们在接下来的内容中将其称为ImageNet),
以及其超集ImageNet-21k,包含21k个类别和1400万张图片(Deng等人,2009年),
(Image可以在https://image-net.org/下载)
以及JFT(Sun等人,2017年),其中包含18k个类别和3.03亿张高分辨率图片
(JFT为google私有数据集)。
此外,研究团队还在19个任务的VTAB分类套件(Zhai等人,2019b)上进行了评估。VTAB评估了对多样化任务的低数据迁移,每个任务使用1,000个训练样本。
类似Bert的研究工作中的方法, 该研究团队创建了不同大小的模型变体, 如下图所示:

例如,ViT-L/16表示输入块大小为16×16的“Large”变体。请注意,Transformer的序列长度与块大小的平方成反比,因此具有较小块大小的模型在计算上更昂贵。
在训练的过程中:使用Adam(Kingma&Ba,2015年)来训练所有模型,包括ResNets,其中β1 = 0.9,β2 = 0.999,批量大小为4096,并施加高权重衰减0.1,这对所有模型的迁移都很有用
对于微调的过程,使用带有动量的SGD,批量大小为512,对所有模型都是如此
和sota的比较
这个比较中,作者首先选择了Big Transfer (BiT) 和 Noisy Student 这两个模型作为基准。BiT 是一个使用大型ResNets进行监督迁移学习的模型,而 Noisy Student 则是一个使用半监督学习在去除了标签的ImageNet和JFT-300M上训练的大型EfficientNet模型。尽管 Noisy Student 是一个基于EfficientNet的模型而不是CNN,但它在ImageNet数据集上的性能是当前的最先进水平,因此作者将其纳入了比较
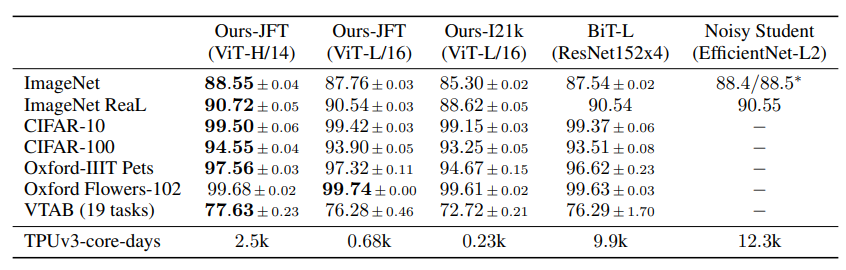
在整张图中, 作者使用了三个模型的变体, 以及另外两个基准模型进行比较. 其中在JFT-300M数据集(google的私有数据集)上进行训练的ViT-L/16, 在性能上超过了BiT-L. 另外, 更大一些的模型ViT-H/14, 进一步展示出了更好的情况, 并且比当前的sota更加节约计算资源和时间.
另外,在上文中提到的19个任务的分类套件中, 研究团队评估了对于不同任务的迁移效果.
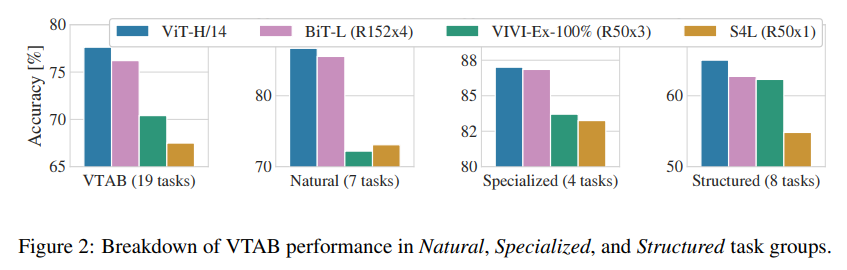
图2将VTAB任务分解为各自的组,并与先前在这个基准测试上的最先进方法进行了比较:BiT,VIVI - 一个在ImageNet和Youtube上共同训练的ResNet模型(Tschannen等人,2020年),以及S4L - 在ImageNet上进行监督和半监督学习的方法(Zhai等人,2019a)。ViT-H/14在自然和结构化任务上的表现优于BiT-R152x4和其他方法。在专业化任务上,前两个模型的性能相似
数据集大小的影响
为了研究归纳偏置以及数据集规模, 研究团队将模型训练在随机子集的9M、30M和90M以及完整的JFT-300M数据集上.相比于ResNets,在较小的数据集上,视觉Transformer更容易过拟合,尽管计算成本相当。例如,ViT-B/32比ResNet50稍快;在9M子集上表现更差,但在90M+子集上表现更好。对于ResNet152x2和ViT-L/16也是如此。这个结果强化了一个直观:卷积的归纳偏差对于较小的数据集是有用的,但对于更大的数据集,直接从数据中学习相关模式是足够的,甚至有益的。
在卷积神经网络中,归纳偏置是指网络结构本身对于数据的假设或倾向。具体来说,卷积神经网络在设计中引入了一些假设,这些假设有助于网络更好地理解输入数据。这些假设可以是关于数据的局部性、平移不变性、尺度不变性等等。
例如,卷积神经网络在设计上假设了图像数据具有局部相关性,即相邻像素之间的关系更密切。因此,卷积操作可以有效地捕捉到图像中的局部特征。另一个例子是池化层,它假设图像中的特征在位置上的变化不会影响整体特征的识别。这些假设可以让网络更高效地学习和泛化,但有时也可能限制了网络对于某些复杂模式的学习能力。
在小一些的数据集上进行训练, 少量数据难以支持较大规模的模式学习, 在这样的条件下更适合使用归纳偏置来减少学习压力, 但同时归纳偏置也省去了一些原本可以学习的部分和模式, 因此在有足够的数据进行支撑的时候, 训练学习是比归纳偏置更有效的方法
2.vit结构解析
2.1 vit的大致结构
vit的大致结构如下:
简单来说, vit实现的功能除了完整的将图像转化以及进行一些自己设置的分类以外, 主要使用了还是经典的transformer中的encoder的架构, 正如论文中所说, 实现的就是nlp在图像识别方便的应用
按照功能,可以简单的将vit的结构划分为三个部分 在使用注意力机制的时候,最小限度的改动(encoder部分甚至没有改动), 将图像切分重排, 作为tokens
- 图像分割处理: 将图像转化为transformer能接受的序列
- 注意力机制: 经典encoder的实现
- 分类感知机: 最后的处理分类
2.2 vit的图像分割
vit的图像分割的实现方法, 我们这里将使用一张尺寸为(3, 96, 96)的图片来做距离(3是图片的频道数量, 96分别是图像的宽度和高度, 在案例和所引用的代码中, 默认图片的宽度和高度是一致的)

vit的处理思路就是, 将图片拆分为多个patch, 也就是按照固定的大小, 将图片切割, 然后重新排列为一个序列. 我们选取切割的尺寸为32*32, 这样子切割可以得到九个小图, 也就是我们所说的patch, 案例里一共划分出来九个patch
( 注: 在代码实现中,要求( 总面积 % patch面积 )是整数, 也就是能完整分割, 不留下残次部分 )

将patch排列,这里每个patch为(3, 32, 32), 并且形成了这样一个一维序列patches, 在这里的每个patch都将会转化成token, 也就是我们常说的词向量, 在传统的nlp任务中, 通过词嵌入实现词和向量的转化, 在这里也很类似: 首先会把图片拉长, 将这个序列转化为二维数组
[ 9 , 3 , 32 , 32 ] ----> [ 9 , 3072 ]
这就类似词嵌入向量, 在正常的transformer的序列处理中, 我们需要为每个词向量都加上一个特殊的位置信息, 这一操作被称之为位置编码, 意为给自然语句加上一些序列关系. 在这个vit的架构中也是一样, 图像在二维中本身就存在一些空间和位置信息, 但是单纯的排列起来会破坏这种空间关系,导致一些不平衡和错误, 因此在这里, vit构建了一个可学习的位置编码信息, 并将其加载我们的序列上
pos + patch_tokens
在具体的实现中, pos是形状和patch_tokens一致的张量, 所做的操作也是按位相加. 这个似乎有些反直觉, 但事实如此, 有种解释之一是"为了数学计算更加简洁,并且尽可能保存其他的序列关系"(说实话怪怪的,能理解但是也好像不理解...). 另外从数学的角度来说, 拼接再经过线性层,和直接相加是等价的.
按照按自己的粗浅理解,画了这样一张图当作证明过程
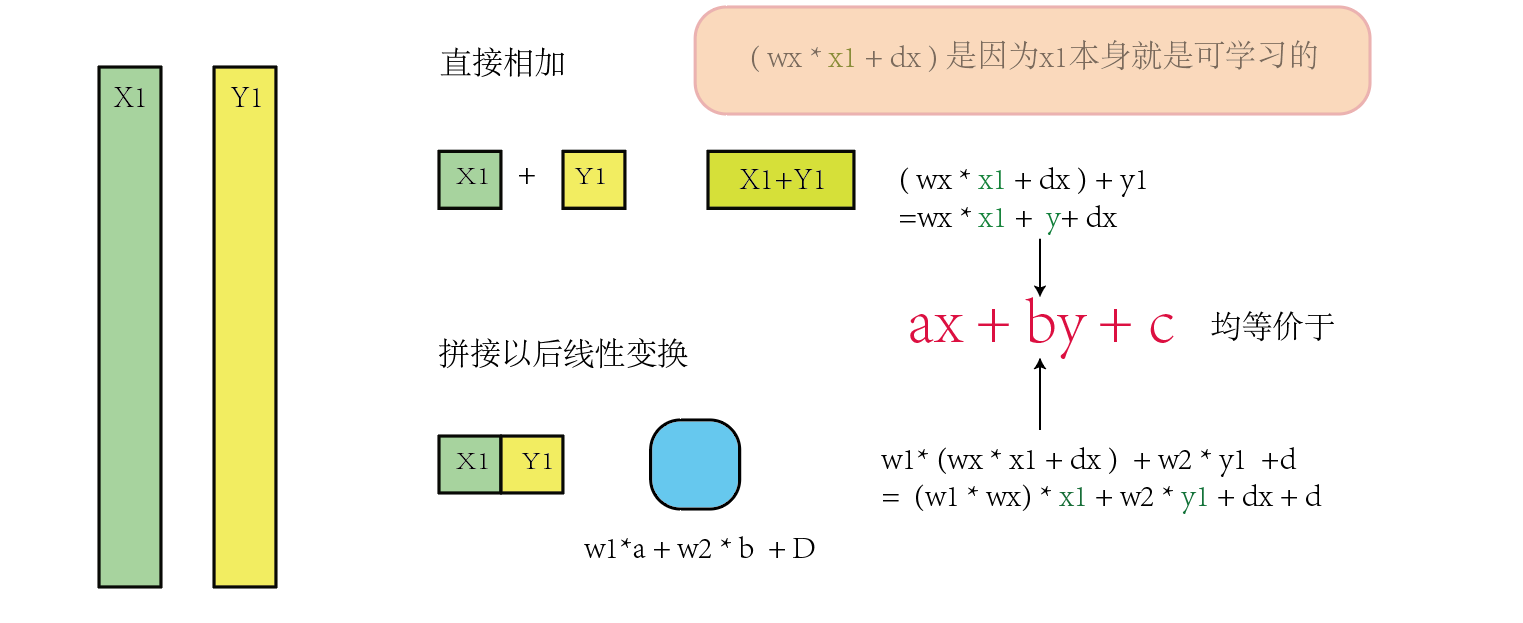
如图所示,我们假设输入的两个都是通道数目为1的,x为pos_embedding y为token, 因为x可以训练学习的参数, 在这里我们加上了一个训练表示.
除此之外,因为一个输入原本是一个图片, 是二维的信息, 在pos的尝试中, 作者同样测试了二维信息的效果
类似这样:
[0,1,2,3,4,5,6,7,8]
变为
[(0,0),(0,1),(0,2)]
[(1,0),(1,1),(1,2)]
[(2,0),(2,1),(2,2)]
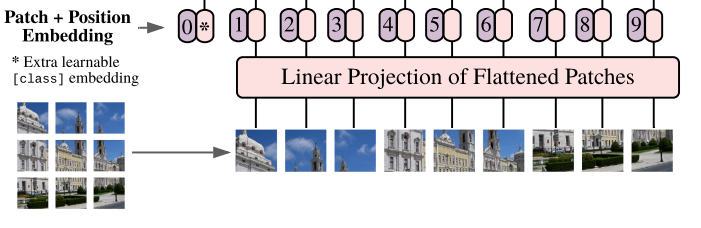
如图所示, 在经过展平层以后, 会进行一个拉直操作,变成常规的tokens集合, 同时通过vit独有的位置编码手段实现.
但是该图片中存在一个问题就是, 我们划分出来九个patch, 按理说应该是划分出九个token, 但是图中展示出了一个新的0号token. 这个结构在bert中被称之为cls_token(事实上在这里也是这样子命名的, 在vit的处理中, 这同样是一个可以学习的张量, 尺寸和其他token一致) , 通过注意力机制中的query key来学习获得其他token的信息, 可以用来代表整个序列
这样做的目的是在经过注意力交互以后,cls_token得到一个可以代表整张图特征的向量, 当然卷积操作也是其中的一种做法, 将多个token拼接, 卷积池化等等操作,同样可以得到一个符合预期结果的特征, 作者在这里做了测试,发现同样可用, 并且在pytorch的实现里, 也同样提供了这样一个可选参数来选择特征提取的形式
为什么这里不直接把图像进行展开, 作为一维数据直接进入nlp中:
首先: 将一张图完全展开, 哪怕是3*96*96的图片, 展开以后也是模型不可承受之重(力大砖飞), 并且这样的展开会完全破坏图片的空间性, 也就是完全抛弃掉了卷积的依赖偏置, 大量的数据也不一定计算出结果
因此, cv领域才会大规模使用cnn, cnn可以一定程度上保持和提取模型固有的空间特征, 但是cnn可以提取的空间范围是有限的太大了没意义, 太小了更没意义.
而RNN同样也是被考虑的一种情况, 根据时间步可以计算出依赖, 但是串行计算肯定会对计算资源带来极大的困扰
因此引入transformer的自注意力机制, 可以一定程度上解决上述两个问题.
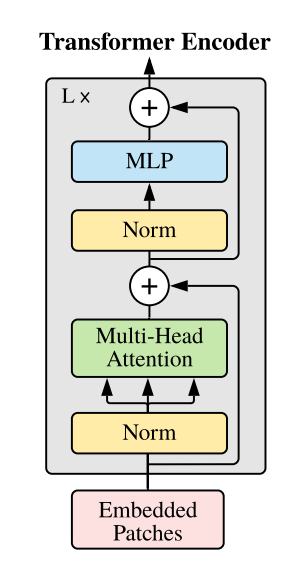
2.3 encoder的注意力机制学习
encoder的阶段直接应用了transformer中的架构, 没有做出什么调整, 目的是通过解码器实现注意力的交互, 让token0可以学习到整个序列的特征情况,
如图所示, 在经过注意力机制的交互以后, 我们其实只需要cls_token的学习结果, 1-9的token其实更多的只是作为辅助学习的资料
transformer的部分从概念来说很好理解,无非就是传入, 使用多头注意力机制, 只是代码实现实在是有些复杂...将在下面的模块细致解释
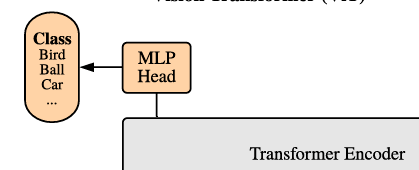
2.4 分类器
最终的分类器部分是一个全连接层的实现
3.vit的代码实现
vit的代码实现参照的是github:https://github.com/ViceMusic/vit-pytorch , 是该作者基于pytorch实现的框架, 使用的案例方法已经写在对应的仓库中了
举个例子, 该库下的一个常用案例为: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256, # 图片的尺寸
patch_size = 32, # 每个补丁的大小 计算出64个patch
num_classes = 1000, # 最后的分类器分成多少类 和具体的任务有关
dim = 1024, # transfromner的大小, 这里应该指的就是cls token的输出结果
depth = 6, # 多少个encoder块堆叠
heads = 16, # 分成16个注意力头部
mlp_dim = 2048, # MLP的维度
dropout = 0.1, # 这两个衰减率
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256) # 一张图 三通道 高256 宽256
#preds = v(img) # (1, 1000) # 预测输出,这是1000个类, 因为本身是对其预测
3.1 完整架构
vit的完整架构如下
1 | class ViT(nn.Module): |
接下来按照大致结构来安排对应的内容
3.2 图像切割部分
首先将图像插入变成可识别的序列, 在这个阶段, 首先需要确定的就是图片的高度和宽度, 以及拆分以后的patch的大小, 并且根据这计算出多少个patch, 以及每个patch的大小
1 | # 首先默认高度和宽度是一致的 |
在词处理的时候,首先要经过这样一个层, 进行词向量嵌入处理
1 | x = self.to_patch_embedding(img) # 先拆分为词向量用于处理 [b, n , v] |
这一层是以这种方式实现的, 借用了einops包中的rearrange函数, 实现一些重排和整型操作, 实际就是将其拆分为tokens einops的实现怪怪的, 用不明白这个包()
1 | self.to_patch_embedding = nn.Sequential( |
随后, 像是上一个部分所说, 需要创建一个cls_token, 在vit中构建一个可学习的张量. 同时对于位置编码, 同样需要创建一个可以学习的位置编码信息.形状如代码所示
1 | # Parameter是用来注册可学习参数的() |
得到这两个可以学习的张量以后, 首先将cls_token使用类似广播机制的方法, 将整个token拼接到每个tokens的最前端
b ,n ,dim ----> b ,n+1 ,dim
先完成cls_token的扩展, 然后拼接, 最后加上编码信息
1 | cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b) # 相当于进行了一个广播操作扩展到了每个批次 |
由此,就完成了图像转化为序列, 并前加上token0和位置信息的需求
3.3 transformer的编码处理
在vit中直接使用了完整transformer框架: 写在注释中了
1 | # transfromer的实现 |
3.3.1 多头注意力子块
多头注意力机制, 指的是将输入数据投入注意力机制, 重复多次以后, 将每一次的结果进行拼接. 从逻辑上说, 通过学习安排, 不同的头部会注重不同的关键点, 比如对一张图片的处理:
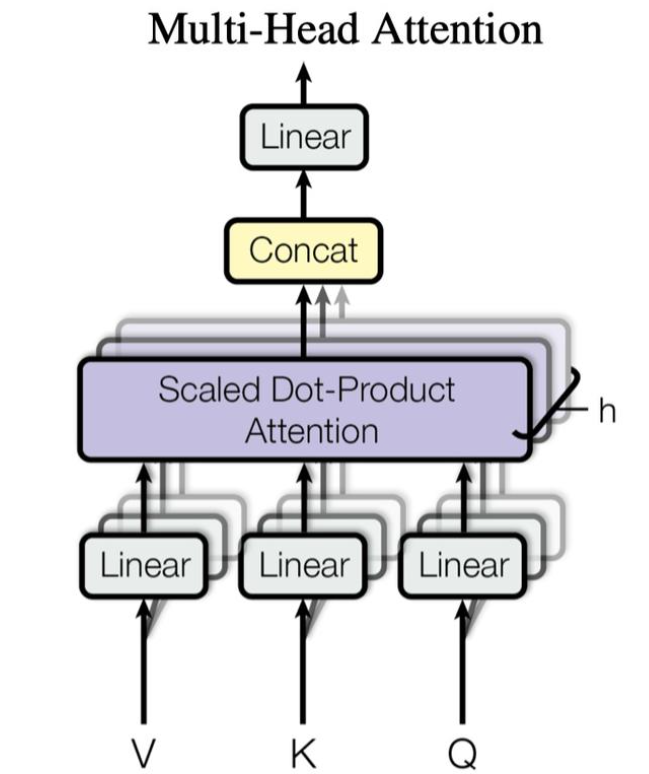
多头注意力子块的实现机制如下所示: 简单来说所做的事情就是先将最后一个维度扩大为原来的三倍
随后将最后一层三等分, 拆分出独立的k q v 三个维度, 但是和原本一样尺寸的张量
如图所示, 我们先通过某种手段(可以是矩阵学习)将输入拆分为V,K,Q三个维度的张量, 随后, 我们根据已知的头部数目h, VKQ分别给拆分成多个头部
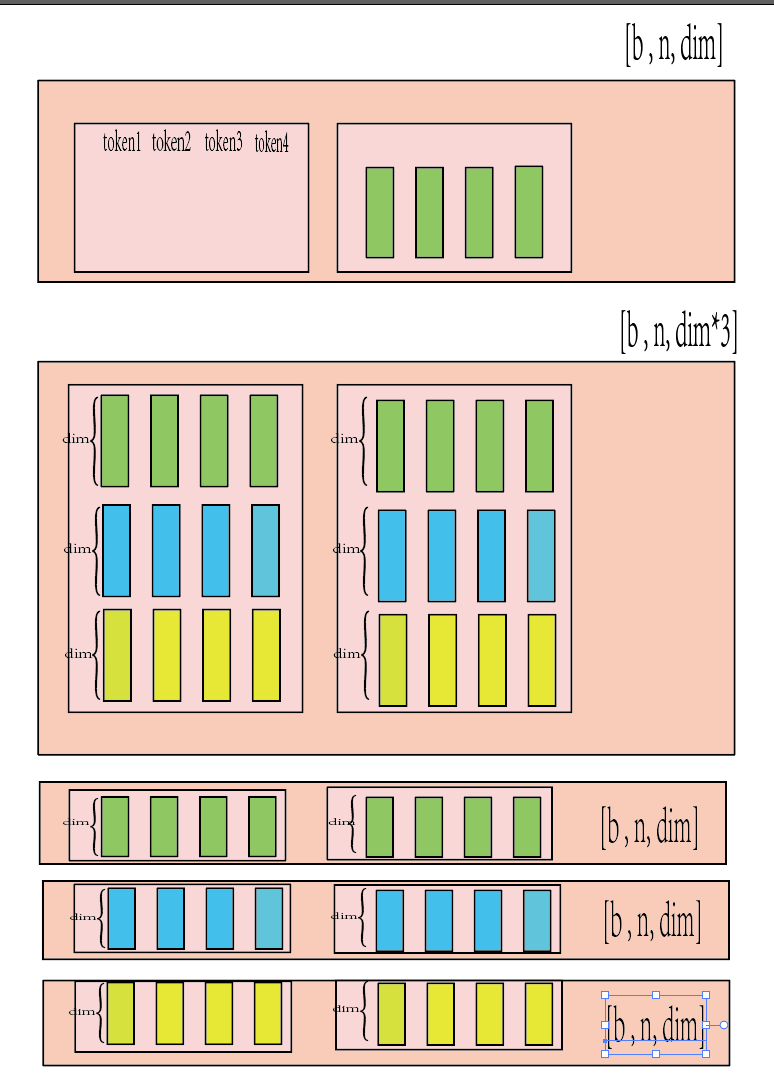
以 V(value为例子):
V的尺寸为(b, n , dim), 使用einops包可以实现转化操作, 将数据转化为:"每个头部下包含(所注意)的token"
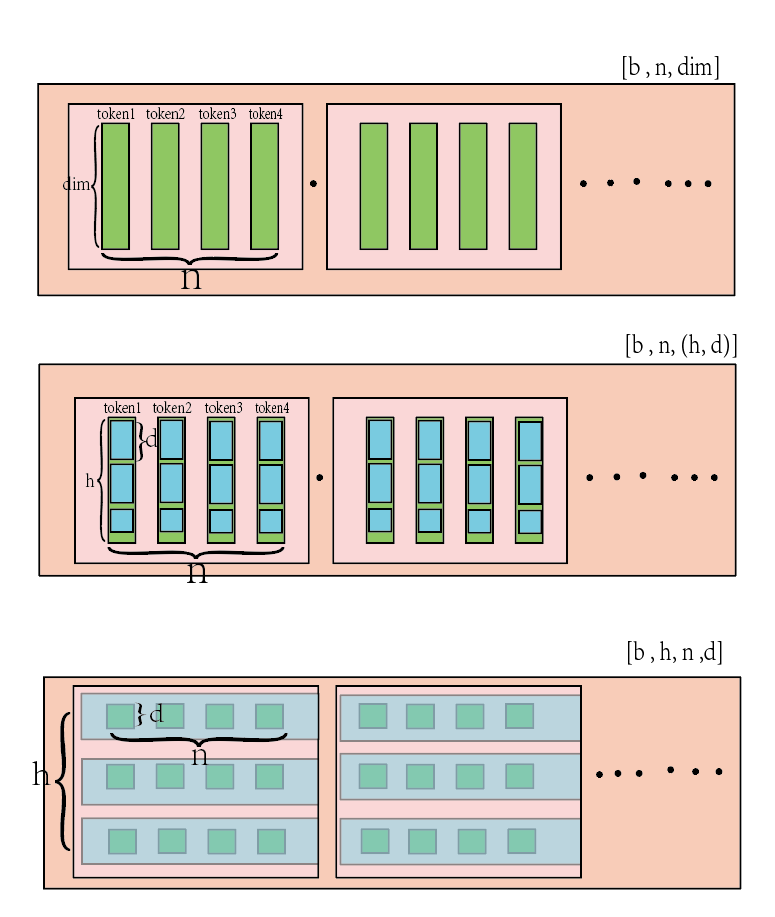
多头注意力子块的实现机制如下所示: 简单来说所做的事情就是先将最后一个维度扩大为原来的三倍
随后将最后一层三等分, 拆分出独立的k q v 三个维度, 但是和原本一样尺寸的张量
紧接着在每个维度中, 计算出要拆分的头h, 和每个头的长度d, 进行拆分并且整型
从"每个token拆分成多少个头"---> '每个头部下多少个token'
进行scaled-dot-product-attention计算(最常用的注意力处理方式), 得到的结果最终重新恢复为原本的张量格式
关于kqv以及sdpa机制, 后续会单独再transformer的论文解读中说明
1 | class Attention(nn.Module): |
3.2.2: 前馈层子块
很简单的一个多层感知机的处理 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 前驱层就是一个正常的MLP, 一个深度网络的处理
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
4.总结
论文的conclusion
我们已经探索了将Transformer直接应用于图像识别。与以往在计算机视觉中使用自注意力的工作不同,除了初始的块提取步骤外,我们没有在架构中引入图像特定的归纳偏置。相反,我们将图像解释为一系列块,并通过标准Transformer编码器(类似于NLP中使用的方式)对其进行处理。这种简单但可扩展的策略,结合在大型数据集上进行预训练,表现出了出乎意料的良好效果。因此,Vision Transformer在许多图像分类数据集上达到或超过了最先进水平,同时相对较便宜地进行了预训练。
尽管这些初步结果令人鼓舞,但仍然存在许多挑战。其中一个挑战是将ViT应用于其他计算机视觉任务,比如检测和分割。我们的结果,结合Carion等人(2020年)的研究,表明了这种方法的潜力。另一个挑战是继续探索自监督预训练方法。我们的初步实验显示了自监督预训练的改进,但自监督和大规模监督预训练之间仍存在较大差距。最后,对ViT的进一步扩展很可能会带来更好的性能
论文的人为总结:
论文创新点:
ViT的创新在于将Transformer模型成功地应用于图像领域,并且在一定程度上挑战了传统的卷积神经网络在图像处理中的统治地位. ViT将图像解释为一系列块(patches),并将其作为序列输入到Transformer模型中,而不是使用传统的卷积层。这种方法消除了对于卷积操作的依赖,使得模型更加灵活。使用Transformer中的自注意力机制来捕获序列中不同块之间的关系。这种注意力机制允许模型在处理序列数据时考虑全局依赖关系,而不仅仅是局部关系。
个人使用情况
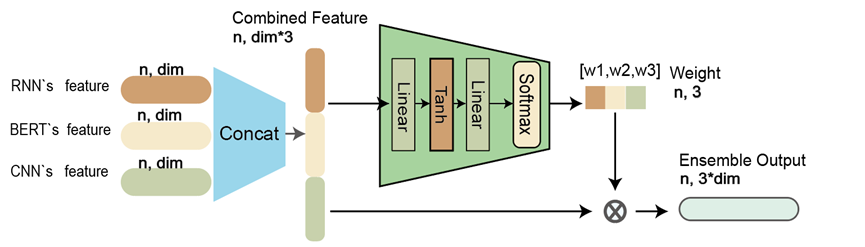
位置编码的实现: 位置编码的实现不同于常规的concat, 而是用了直接相加的手段, 至少在这篇论文的大背景下是相等可证的. 但是将这种直接相加的方法并非适用于所有的情况, 在当前的工作中遇到这样的情况: 在集成学习中得到三个输出, 直接将三个输出(赋予权重/不赋予权重)直接相加并正则化, 并没有得到特别好的情况,并且逻辑上似乎讲不通
cls_token: 使用一个空白的token, 通过注意力机制的交互性, 去学习其他的序列单元的信息, 起到了一个特征提取的作用. 但是作者同时在全文中也提到了一点: 对于交互以后的token序列, 仍然可以使用CNN去浓缩,提取一个较短的特征作为分类器层的输入. 团队进行了尝试,发现效果区别不大.
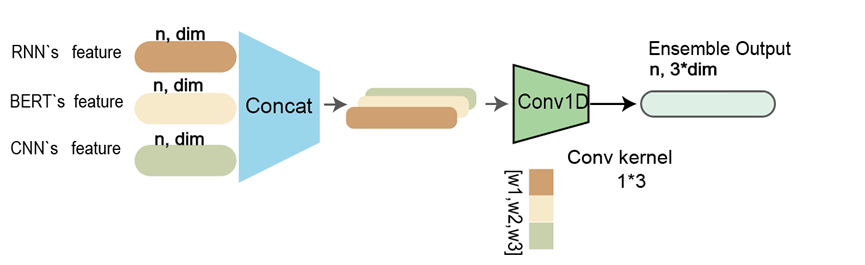
另外在目前的工作中, 需要对三个模型的输出计算一个权重数值, 虽然无法照搬cls_token机制, 按时我们仍然按照作者的思路构建了一个类似的CNN卷积核, 用来代替计算出的权重. 在NA12878不平衡人类数据集上, 效果也和我们的attention_weight机制所差无几. 在更大数据集上的表现尚未可知(猜测可能略差于attention_weight)
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 xranudvilas@gmail.com

